Introduction
Hey there! Have you ever wondered how artificial intelligence (AI) can create stunningly realistic images that seem like they were taken by a professional photographer? Well, get ready to dive into the fascinating world of Generative Adversarial Networks (GANs), where AI takes image generation to a whole new level!
In this blog post, we’re going to explore the power of GANs and understand how they work their magic.
What is a Generative Adversarial Network?
Generative Adversarial Networks, or GANs for short, are a type of Artificial Intelligence (AI) Model that consists of two competing Neural Networks:
1. Generator
2. Discriminator
These networks work together to generate new data that closely resembles the training data provided.
The architecture of a GAN is designed in such a way that the generator network tries to create synthetic data samples while the discriminator network aims to distinguish between real and fake samples. This creates a “game” between these two networks, where they continuously learn from each other through an iterative process.
So how does this all work? The generator starts by generating random noise and passes it through its layers to produce an output. Meanwhile, the discriminator takes both real and generated images as input and predicts whether each sample is real or fake. Through this feedback loop, both networks improve over time until the generator becomes proficient at producing realistic-looking images.
GANs have gained popularity due to their ability to generate high-quality images, even surpassing what humans can create. They have been used in various applications like image synthesis, style transfer, image editing, and even video generation.
Architecture of GAN
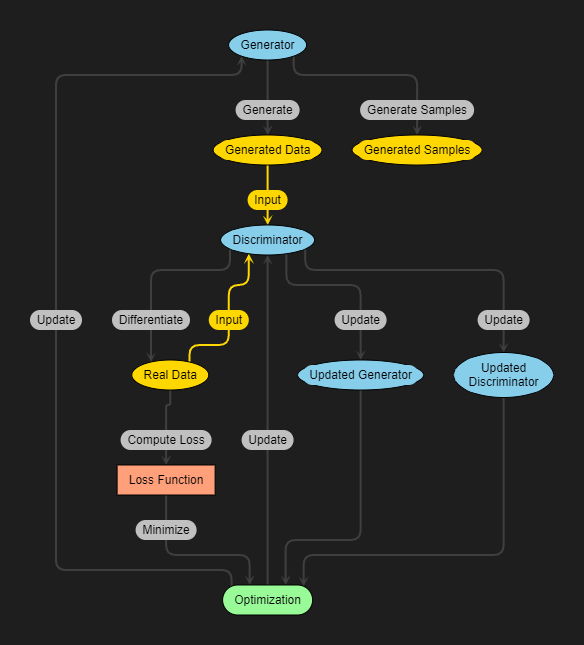
The generator takes in random noise as input and generates fake images that aim to resemble real ones. It learns to create these images by continuously improving its output based on feedback from the discriminator.
On the other hand, the discriminator’s job is to distinguish between real and fake images. It receives both real images from a dataset and generated images from the generator. The discriminator learns to correctly identify which are real and which are fake through training.
Both models work together in a competitive process, where they constantly try to outsmart each other. The goal is for the generator to generate increasingly realistic images, while the discriminator becomes more skilled at identifying fakes.
This back-and-forth process between the generator and discriminator leads to continuous improvement in generating high-quality synthetic data.
By understanding this architecture, we can see how GANs leverage adversarial training techniques to produce impressive results in image generation tasks. Stay tuned for more insights on GANs!
How does a GAN work?
The generator takes random noise as input and tries to create fake images that resemble real ones. It starts with crude and noisy outputs but improves over time through training. On the other hand, the discriminator’s role is to distinguish between real and fake images. It learns from a dataset containing both real and generated images, becoming better at identifying fakes.
During training, these models engage in a battle where each one tries to outsmart the other. The generator aims to produce more convincing images while the discriminator strives to accurately identify them. As they continuously iterate this process, they both improve their capabilities until eventually reaching a point where it becomes difficult for humans to differentiate between real and generated pictures.
It’s important to note that GANs require large amounts of data for effective training. The more diverse and representative the dataset is, the better results can be achieved. Additionally, finding an optimal balance between stability (avoiding mode collapse) and diversity (producing varied samples) can be challenging but crucial for successful GAN performance.
Now that we have explored how GANs operate at a high level, let’s delve deeper into some specific types of GAN models in our next section! Stay tuned!
Types of GAN Models

The first type is the Generator model.
On the other hand, we have the Discriminator model.
These two models work together in a dynamic process where they continuously improve their performance through competition with each other—hence, “adversarial” in generative adversarial networks!
There are also variations within these two primary types of GAN models depending on specific requirements or applications. For example, Conditional GANs allow us to control what kind of output we want from our generator by providing additional information during training.
With such diverse options available, developers can choose from various GAN architectures depending on their project goals and desired outcomes.
Generator Model
![]()
The generator model is the heart and soul of a Generative Adversarial Network (GAN). It’s responsible for creating new data that resembles the training set it was given. Think of it as an artist who takes inspiration from a collection of paintings and then creates their unique masterpiece.
This model works by taking random input, often referred to as “noise,” and transforming it into something meaningful. The noise can be thought of as a starting point for creativity, like a blank canvas waiting to be filled with colors and shapes.
The generator uses various mathematical operations to transform this noise into an output that resembles real data. For example, in image generation tasks, the generator may convert the noise into pixel values that form an image.
But here’s where things get interesting: the generator doesn’t know what specific images it needs to create. It learns through trial and error, constantly adjusting its parameters based on feedback from another crucial component of GANs – the discriminator model.
The generator model in GANs serves as an artistic genius that turns randomness into coherent representations resembling real data.
Discriminator Model

The main objective of the discriminator is to learn how to classify whether an image is real or generated by the generator. It takes in input images and outputs a probability score indicating how likely it think that image is real. The goal of training the discriminator is to make it better at differentiating between real and fake images over time.
The architecture of the discriminator typically consists of convolutional layers followed by fully connected layers. These layers help extract relevant features from the input images and make predictions based on those features.
During training, both the generator and discriminator models are updated simultaneously in an adversarial manner. The generator tries to generate more realistic images to fool the discriminator, while the discriminator aims to become more accurate in classifying real versus generated images.
By iteratively improving each other’s performance through this adversarial process, both models gradually improve their abilities until they reach a point where it becomes difficult for humans to distinguish between generated and real images.
Understanding how both components – generator, and discriminator – work together in a GAN helps us appreciate their combined power in generating highly convincing artificial imagery.
Advantages and Disadvantages of GANs

Advantages of Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) offer the following advantages:
- Image generation that is highly realistic
- Features of generated images can be controlled in a flexible manner
- The ability to learn complex data distributions
- Facilitating cross-domain transfer of learning
- Beyond image synthesis, explore new AI research possibilities
- A disadvantage of Generative Adversarial Networks (GANs) is:
- Mode collapse or convergence issues during training due to instabilities
- Hyperparameter sensitivity, requiring careful tuning
- Effective training requires large datasets
- Concerns about potential misuse of personal information
- Convergence and quality evaluation are difficult
Despite GANs’ exciting potential, it’s crucial to address these limitations for more reliable outcomes in practice.
Disadvantages of Generative Adversarial Networks (GANs)
Disadvantages of GANs:
- Training instability leading to mode collapse or convergence issues
- Sensitivity to hyperparameters affecting performance and training feasibility
- Requirement of extensive datasets for effective training
- Privacy concerns due to potential misuse for generating fake content
- Subjective evaluation of quality and convergence, relying on human inspection
- Importance of acknowledging limitations for practical use and further research for improvement.
Implementation of GANs
Implementation of GANs can be done using various programming languages, but one popular choice is Python3. With its extensive libraries and frameworks like TensorFlow and Keras, Python3 provides a robust platform for developing GAN models.
To implement a GAN in Python3, you’ll need to define the generator and discriminator models. The generator model takes random noise as input and generates synthetic images. On the other hand, the discriminator model learns to distinguish between real and fake images.
Training a GAN involves an adversarial process where the generator tries to fool the discriminator by generating realistic images, while the discriminator aims to correctly classify real and fake images. This iterative process results in both models improving over time.
With Python3’s flexibility, you can experiment with different architectures, loss functions, and hyperparameters to optimize your GAN model’s performance. Additionally, there are numerous online resources such as tutorials and open-source projects that provide code examples for implementing GANs in Python3.
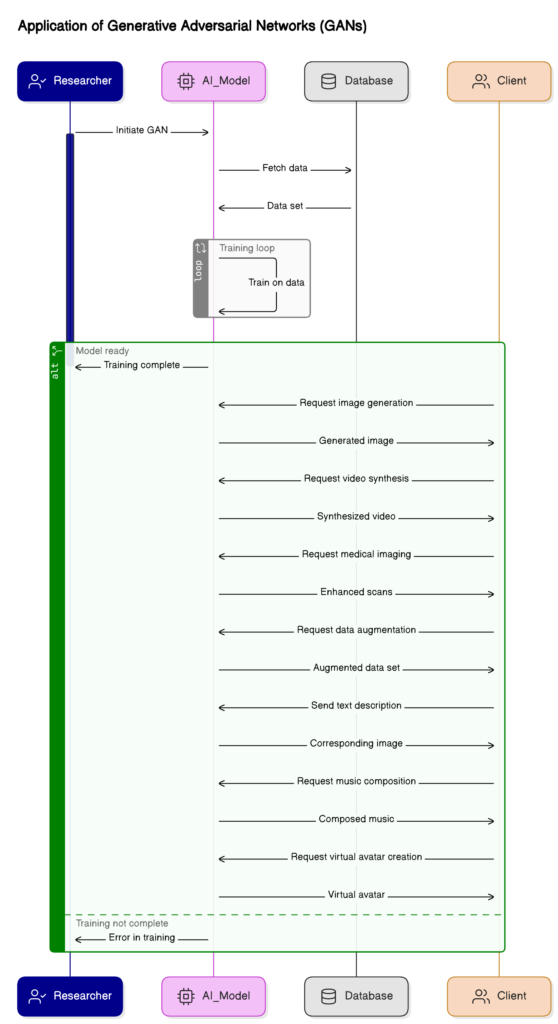
Application Of Generative Adversarial Networks (GANs)
| Application | Description |
| Image generation | GANs excel in creating realistic images with AI, mimicking photographs captured by cameras. |
| Video synthesis | GANs enable the generation of entirely new videos based on existing footage, revolutionizing filmmaking and special effects industries. |
| Medical imaging | GANs aid in medical tasks such as generating synthetic medical data and enhancing low-resolution scans, facilitating accurate diagnosis and treatment planning. |
| Data augmentation | GANs generate additional training samples to enhance the performance of machine learning models across domains like natural language processing and computer vision. |
| Text-to-image synthesis | GANs convert textual descriptions into corresponding images, expanding possibilities in creative content generation. |
| Music composition | GANs contribute to music creation by generating melodies and compositions, offering innovative approaches to music production. |
| Virtual avatars | GANs produce virtual avatars with human-like expressions, enhancing interaction in virtual environments and gaming. |
Use Cases and Applications
Generative Adversarial Networks (GANs) have a wide range of applications across various industries. Let’s explore some of the fascinating use cases where GANs are making a significant impact.
One notable application is in the field of art. GANs can generate stunning pieces of artwork that mimic famous artists’ styles, creating new and unique paintings that captivate viewers. These generated artworks not only showcase the power of AI but also offer new possibilities for artistic expression.
Another exciting use case is in fashion design. GANs can be used to create virtual fashion designs, allowing designers to quickly prototype and iterate on their ideas without the need for physical manufacturing. This saves time, and resources, and allows for more creative experimentation.
In the medical field, GANs are being utilized for tasks like generating synthetic medical images or enhancing low-resolution scans. This technology enables doctors to visualize complex anatomical structures more accurately and aids in diagnosis and treatment planning.
GANs also have applications in video game development by generating realistic characters or environments with minimal human intervention. This speeds up the game development process while maintaining high-quality graphics.
Furthermore, GANs find utility in data augmentation techniques for training machine learning models. By generating additional labeled data from existing datasets, GANs help improve model performance without requiring extensive manual labeling efforts.
These examples demonstrate just a fraction of what can be achieved using Generative Adversarial Networks (GANs). The versatility and potential of this technology continue to expand as researchers explore new applications across diverse domains.
Examples of Generative Models

Another example is the PixelRNN, which generates images pixel by pixel using recurrent neural networks. By training on large datasets, PixelRNN can generate stunningly detailed and high-resolution images that are almost indistinguishable from real photographs.
StyleGAN is another powerful generative model that has gained attention for its ability to synthesize highly realistic human faces. It uses a progressive growing technique to gradually increase image resolution while maintaining high-quality results.
CycleGAN is an exciting application of generative models in computer vision. It can transform images from one domain to another without paired training data. For example, it can convert horse images into zebra-like ones or turn summer scenery into winter landscapes!
These are just a few examples showcasing the incredible potential of generative models in various domains such as image generation, style transfer, and even text-to-image synthesis! With ongoing research and advancements in AI technology, we can expect even more innovative applications and breakthroughs with generative adversarial networks like GANs leading the way!
Remember to explore further reading resources at the end of this article for more information on these fascinating topics!
GANs and Convolutional Neural Networks
GANs and Convolutional Neural Networks (CNNs) are two powerful techniques in the field of artificial intelligence. CNNs, also known as ConvNets, are commonly used for image classification tasks. They excel at extracting features from images by applying convolutional filters.
On the other hand, GANs take things a step further by not only classifying images but also generating new ones. The combination of GANs and CNNs has led to remarkable advancements in image generation.
By using a CNN as the discriminator model in a GAN architecture, we can train the generator model to produce realistic synthetic images that fool even the most discerning human eye. This is achieved through an adversarial training process where both models continuously improve their performance.
The strength of CNNs lies in their ability to learn hierarchical representations of visual data. These learned features serve as input for the GAN’s discriminator model, enabling it to distinguish between real and generated images with high accuracy.
Combining the power of CNN-based feature extraction with the generative capabilities of GANs opens up exciting possibilities for various applications such as art generation, video game design, medical imaging, and more.
When GANs harness the potential of convolutional neural networks, they become even more effective at generating realistic and high-quality images. By leveraging deep learning techniques like these, researchers continue pushing boundaries and unlocking new opportunities in artificial intelligence research.
Conditional GANs

Conditional GANs (cGANs) take the concept of GANs to the next level by adding a conditional component. In traditional GANs, the generator creates images from random noise without any specific guidance. However, cGANs introduce an additional input that provides some form of conditioning information.
This conditioning information could be anything – it could be a class label, text description, or even another image. By incorporating this extra input, cGANs can generate more targeted and controlled outputs.
For example, let’s say we want to generate realistic images of cats. We can train a cGAN using labeled cat images as the conditioning information. The generator will then learn to produce cat-like images based on this additional input.
The ability to conditionally generate images opens up a wide range of possibilities in various fields such as art, fashion design, and even virtual reality. With cGANs, we have greater control over what our generated content looks like.
However, it’s important to note that training cGANs can be more challenging than training traditional GAN models due to the added complexity of incorporating conditional inputs. Properly designing and balancing these networks requires careful consideration and experimentation.
Conditional GANs offer exciting opportunities for generating highly customized and specific content based on user-defined conditions or criteria. Whether it is creating personalized avatars or generating unique artwork based on textual prompts – with conditional GANs in play – the sky’s the limit!
Application examples using GANs

Another exciting application is in healthcare, where GANs have been used to generate synthetic medical images for training algorithms or simulating rare diseases for diagnostic purposes. This allows researchers to augment their datasets with diverse samples without compromising patient privacy.
In the fashion industry, GANs have been utilized to generate new clothing designs based on existing styles or trends. This enables designers to explore creative possibilities quickly and efficiently, leading to increased innovation within the industry.
GANs have also found applications in video game development by generating virtual environments and characters that enhance gameplay experiences. By using GAN-generated content, developers can save time and resources while still delivering visually stunning games.
Furthermore, GANs have shown promise in natural language processing tasks like text-to-image synthesis or text translation. These models enable users to describe an image conceptually with a few words and then generate a corresponding image.
These are just a few examples of how Generative Adversarial Networks are being applied across different fields. The potential of GANs continues to expand as more innovative use cases emerge.
Conclusion
In this blog post, we have explored the fascinating world of Generative Adversarial Networks (GANs) and their potential in image generation. GANs are a powerful form of Artificial Intelligence that consists of two models – the generator and the discriminator – working together to create realistic images.
We discussed how GANs work by pitting these two models against each other, with the generator trying to create convincing fake images while the discriminator tries to distinguish between real and fake images. This adversarial training process allows GANs to continually improve and generate more realistic outputs.
We also looked at some advantages and disadvantages of using GANs. On one hand, GANs can produce incredibly high-quality synthetic data which has numerous applications in various industries. On the other hand, they can be challenging to train and prone to generating biased or unrealistic outputs.
Additionally, we delved into different types of GAN models such as conditional GANs and their application examples across various domains like art generation, video synthesis, and even healthcare research.
Generative Adversarial Networks offer immense potential for creative AI applications. As technology continues to advance, we can expect further advancements in GAN algorithms resulting in even more impressive image generation capabilities. So keep an eye on this exciting field as it evolves!
Further Reading and Resources
So there you have it, an in-depth exploration of the potential of Generative Adversarial Networks (GANs) and the power they hold in image generation. These AI models have revolutionized the field of computer vision and opened up new possibilities for creative expression.
If you’re interested in delving deeper into GANs and learning more about their implementation and applications, here are some further reading resources that can help expand your knowledge:
- “Generative Deep Learning” by David Foster – This book provides a comprehensive introduction to generative modeling techniques, including GANs, along with practical examples and code implementations.
- “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville – This well-known textbook covers various topics related to deep learning, including a detailed chapter on GANs written by one of its creators.
- Papers from top conferences like NeurIPS (Conference on Neural Information Processing Systems) and ICCV (International Conference on Computer Vision) frequently feature groundbreaking research on GANs. Exploring these papers can give you insights into the latest advancements in this field.
- Online tutorials and courses such as those offered by platforms like Coursera or Udacity provide hands-on experience with implementing GAN models using popular frameworks like TensorFlow or PyTorch.
Remember that mastering GANs requires both theoretical understanding and practical application. So don’t hesitate to experiment with different architectures, datasets, or loss functions to unleash your creativity!
By harnessing the power of AI through Generative Adversarial Networks (GANs), we are witnessing incredible advancements in image generation capabilities. From generating realistic artwork to enhancing medical imaging techniques, GANs offer endless possibilities for innovation across various domains.
As technology continues to evolve rapidly, it’s exciting to imagine what lies ahead for generative modeling techniques like GANs. With ongoing research efforts focused on improving stability issues and expanding applications, we can expect even more impressive results in the future.












{kind=link}