Introduction
Ready to dive into the latest and greatest in AI technology, GPT-4o. It’s super smart and can think in real time, whether it’s listening, looking, or reading text. Introducing it, OpenAI’s newest addition to their impressive lineup of multimodal models. This latest version takes the already powerful capabilities of its predecessor, GPT-4, to the next level with enhanced visual comprehension. With advanced talking, seeing, and interacting features within the ChatGPT interface, it promises a more fluid and intuitive user experience.
We can converse with computers in a much more natural way with GPT-4o, or “omni”. As quick as 232 milliseconds, it can understand and respond to text, audio, and images. With English and coding tasks, it is just as good as GPT-4 Turbo, and even better with other languages. Best of all, it is faster and more affordable than GPT-4 Turbo! It excels at understanding audio and images, making it a major advance in artificial intelligence.
Model Capabilities
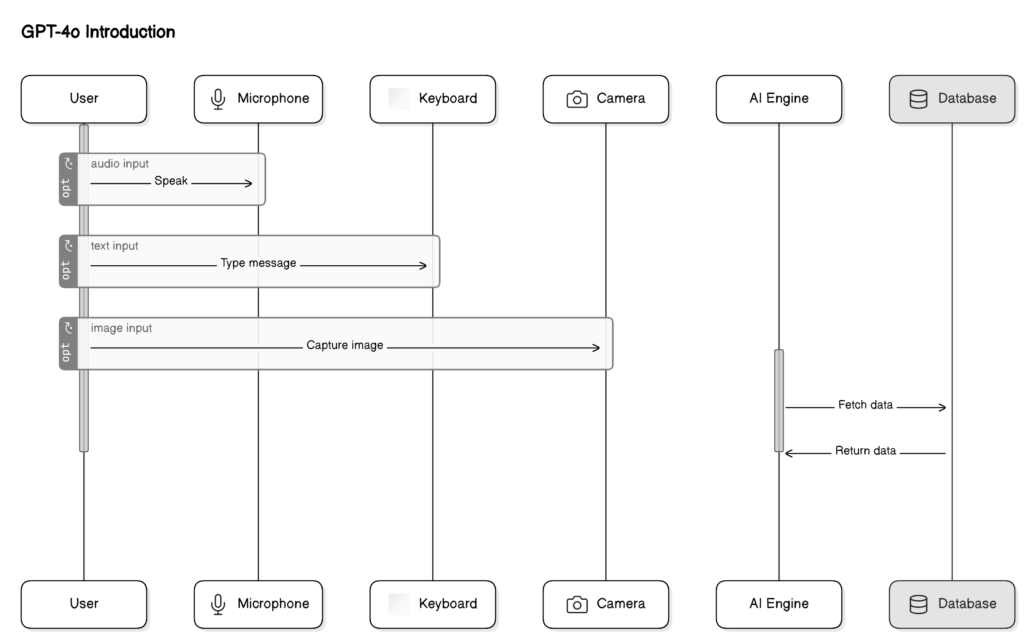
Before it, utilizing Voice Mode on ChatGPT presented challenges. Average delays were 2.8 seconds with GPT-3.5 and 5.4 seconds with GPT-4. This mode operated similarly to a relay race, where three models were involved: one converting speech to text, followed by either GPT-3.5 or GPT-4 processing the text, and finally another model translating it back into speech. However, relying mainly on GPT-4 came with its limitations – it was unable to capture subtleties such as tone, multiple speakers, or background noise, and lacked the ability to incorporate elements like laughter or emotion into its responses.
We trained one model to handle text, vision, and audio together in it, instead of using separate models for each task. This means that everything goes through the same brain, so to speak. However, since this is the first time we’ve done it, we’re only beginning to understand its full potential and where it falls short. As far as what it can do and where its limits lie is concerned, we are just at the tip of the iceberg.
Text Evaluation of GPT-4o
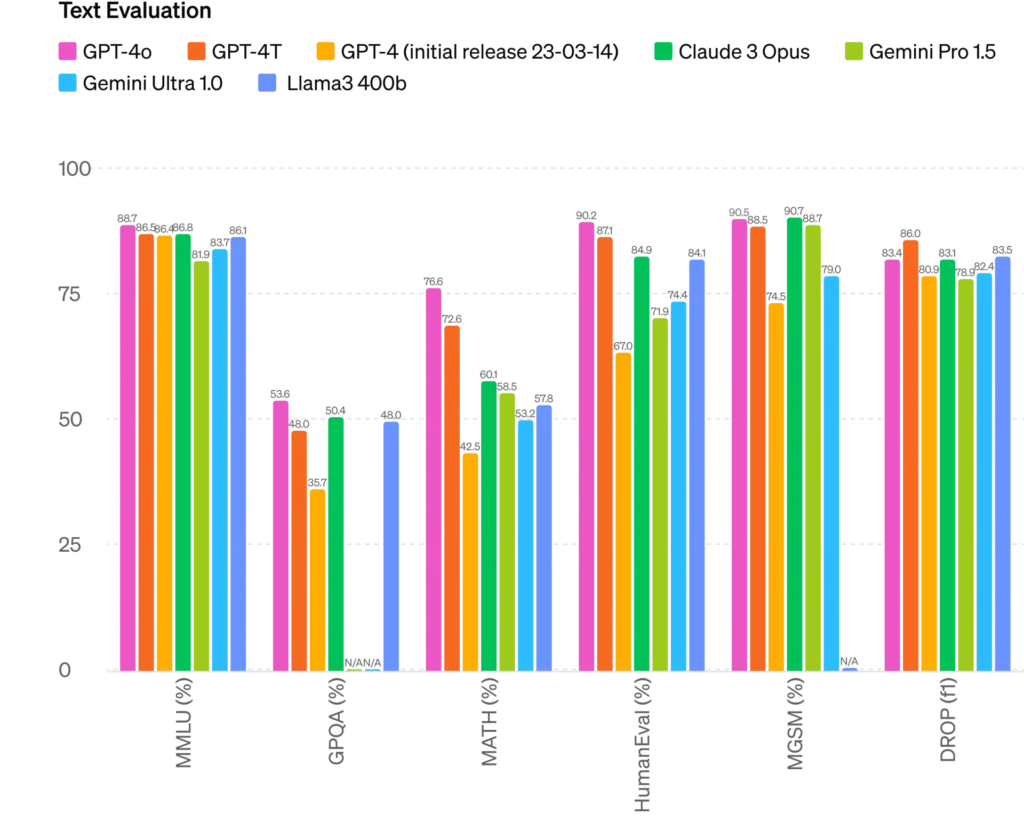
The graph displays the performance of various language models across several benchmarks: MMLU, GPQA, MATH, HHH-Alignment, MGSM, and DROP (f1). The models compared are GPT-4o, GPT-4T, GPT-4 (initial release), Claude 3 Opus, Gemini Pro 1.5, Gemini Ultra 1.0, and Llama3 400b.
Benchmark Performance Breakdown
Number of MMLUs (%)
- GPT-4o (88.7%) was the top performer.
- The second place winner was GPT-4T (86.8%).
- The third place winner is GPT-4 (initial release) (86.6%)
- The lowest performer was Claude 3 Opus (81.9%).
GPQA (%)
- The top performer was GPT-4o (53.6%)
- The second place winner was GPT-4T (48.0%).
- Gemini Pro 1.5 (35.7%) took third place.
- Gemini Pro 1.5 (35.7%) took third place.
Percentage of math (%)
- The top performer is GPT-4o (76.6%)
- The second place winner is GPT-4T (72.6%)
- The third place winner was GPT-4 (initial release) (60.1%).
- In terms of performance, Claude 3 Opus (42.5%) was the lowest performer
HHH-Alignment (%)
- GPT-4o (90.2%) is the top performer
- A second place finish was achieved by GPT-4T (87.1%).
- Gemini Ultra 1.0 (84.9%) placed third
- The lowest performer is Gemini Pro 1.5 (67.0%).
Percentage of MGSM (%)
- The top performer was GPT-4o (90.5%)
- The second place winner is GPT-4T (88.5%)
- Second Place: GPT-4 (initial release) (74.4%)
- Gemini Pro 1.5 (74.5%) performed the worst
(f1) DROP
- The top performer was GPT-4o (86.0%)
- The second place winner was GPT-4T (83.4%)
- Gemini Ultra 1.0 (83.1%) placed third
- Gemini Pro 1.5 (78.4%) is the lowest performing software.
- An analysis of the statistical data
- The mean and standard deviation are shown in the following
Mean and Standard Deviation
GPT-4o:
- The mean is: (88.7 + 53.6 + 76.6 + 90.2 + 90.5 + 86.0) / 6 = 80.93.
- Standard Development: 15.92
GPT-4T:
- It is calculated as follows: (86.8 + 48.0 + 72.6 + 87.1 + 88.5 + 83.4) / 6 = 77.73.
- Standard Development: 15.63
GPT-4 (initial release)
- The mean is (86.6 + 48.0 + 60.1 + 84.9 + 74.4 + 83.1) / 6 = 72.18
- Standard Development: 15.91
Opus 3 of Claude:
- A means of (71.9 + N/A + 42.5 + N/A + 79.0 + N/A) divided by 3 is 67.8.
- Standard Development: 19.81
Gemini Pro 1.5:
- A mean of 66.08 can be calculated by dividing (83.7 + 35.7 + 53.2 + 67.0 + 74.5 + 82.4) by six
- Standard Development: 18.28
Gemini Ultra 1.0
- The average is (86.1 + N/A + 57.8 + 84.1 + 71.9 + 83.5) / 5 = 76.68.
- Standard Development: 11.58
Llama3 400b:
- The mean is (83.7 + 48.0 + 57.8 + N/A + 79.0 + N/A) / 4 = 67.13.
- Standard Development: 15.42
Insights
1. Top performers:
- GPT-4o consistently outperforms other models, with the highest mean score (80.93) and relatively high consistency (15.92).
- The GPT-4T has a mean score of 77.73 and a similar consistency (Std Dev: 15.63).
2. Gaps in performance:
- GPT-4o excels in text and reasoning tasks due to its balance across different benchmarks.
- Gemini Pro 1.5 and Claude 3 Opus have lower mean scores and higher variability, indicating less consistent performance.
3. Areas for improvement:
- Performance and consistency across all benchmarks need to be improved for Gemini Pro 1.5 and Claude 3 Opus.
- Models with missing data (Claude 3 Opus and Llama3 400b) indicate incomplete evaluation and require further testing.
As a result of its superior performance and consistency, GPT-4o is the most robust text evaluation model across various benchmarks. In natural language understanding and reasoning applications, this suggests it is well suited for high reliability and versatility. While other models are competitive in certain areas, they exhibit greater variability and lower overall performance, indicating areas for improvement and development.
Image Generation using GPT-4o
Here is a sample visual narrative generation for “Sally the mailwoman.”
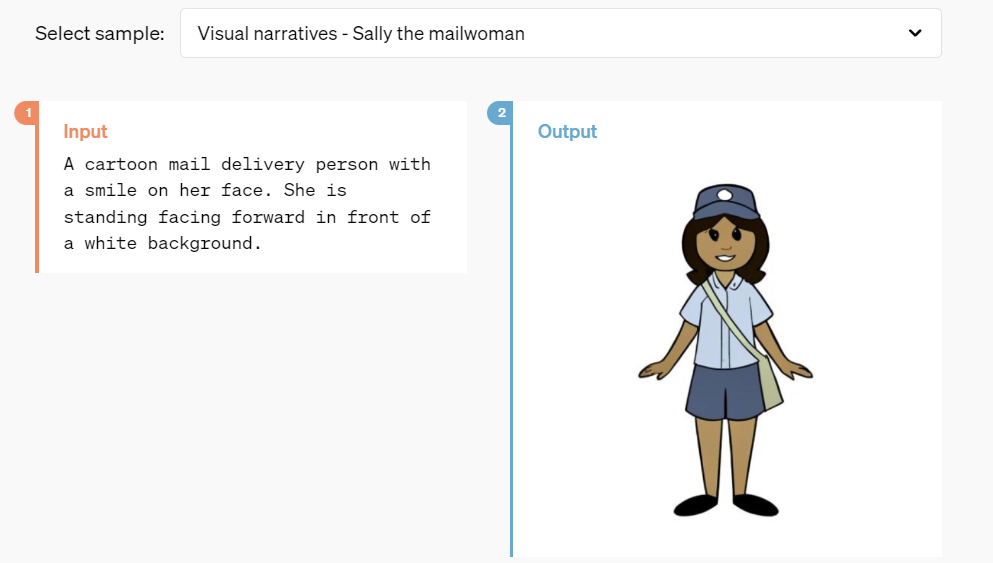
Input description
- text: A cartoon mail delivery person stands in front of a white background with a smile on her face
Output image
- Visual: A cartoon illustration of a mailwoman with a smile. She stands upright, facing forward, dressed in a light blue shirt, dark blue shorts, and black shoes. The background is plain white, as described in the input. She is wearing a cap, a light blue shirt, dark blue shorts, and black shoes.
Analysis
- Accuracy: The output image accurately represents the input description. The character’s smile, pose, and attire match the textual description.
- Details: The uniform and mailbag are accurately illustrated, ensuring the character is recognizable as a mail carrier.
- Simplicity: The plain white background adheres to the input prompt while keeping the focus on the character.
It effectively translates the textual description into a cartoon image, demonstrating the ability to generate accurate and simple visual narratives.
GPT-4o’s audio capabilities

Performance Analysis of Audio ASR
The chart above compares the Word Error Rate (WER) between Whisper-v3 and GPT-4o (16-shot) across different regions. A lower WER indicates better audio speech recognition.
The following are some key observations:
- Languages of Western Europe:
- Whisper-v3: 5% off
- The GPT-4o is 2%
- GPT-4o reduces WER by more than 50% compared to Whisper-v3.
2. Languages of Eastern Europe:
- Whisper-v3: 15% off
- The GPT-4o is 10%
- The WER has been reduced by approximately 33%.
In Central Asia/Middle East/North Africa:
- Whisper-v3: 30% off
- A 20% GPT is applied to GPT-4o
- The WER was reduced by 33%.
The following are the countries in South Asia:
- The Whisper-v3 has been improved by 35%
- The GPT-4o is 25%
- The WER has been reduced by 29%.
The following countries are located in South East Asia:
- Whisper-v3: 15% off
- The GPT-4o is 10%
- WER was reduced by 33%.
The CJK (Chinese, Japanese, Korean):
- Whisper-v3: 10% off
- The GPT-4o is 5%
- A 50% reduction in WER is an improvement.
The summary is as follows:
Overall Performance: GPT-4o consistently outperforms Whisper-v3 in all regions, showing significant improvements in WER.
The largest improvements are observed in regions with traditionally low-resource languages (e.g., Central Asia, Middle East, North Africa, Sub-Saharan Africa).
These improvements suggest that it’s advances in audio speech recognition may be especially beneficial for regions with diverse languages and low resources.
As a result of it’s enhanced audio ASR performance, word error rates across a wide variety of languages and regions have been significantly reduced, with notable gains in areas with limited language resources. Globally, this can lead to better user experiences in speech recognition applications.
Based on the CoVoST-2 BLEU score (higher is better), the bar chart compares the audio translation performance of various models.
- It is OpenAI’s GPT-4o that leads with a BLEU score of around 40.
- Whisper-v3 (OpenAI) scores around 30.
With scores of about 35 and 20, respectively, FastM4T-v2 and FastXLS-R (Meta) perform moderately.
The AudioPalm-2 and Gemini (Google) also perform well, scoring around 37 and 43, respectively.
As a result, GPT-4o and Gemini exhibit superior audio translation capabilities.
Understanding GPT-4o visually
Below is a simplified breakdown of the performance of several models across different evaluation sets:
- The GPT-4o model outperforms other models in most evaluation sets, with notable high scores in AI2D (94.2%), ChartQA (85.7%), and DocVQA (92.8%).
- Although GPT-4T performs well, it generally scores slightly lower than GPT-4o, particularly in MathVista (58.1%) and AI2D (89.4%).
- Gemini 1.0 Ultra and Gemini 1.5 Pro have lower scores than GPT-4o, with significant gaps in AI2D (79.5% and 80.3%) and DocVQA (90.9% and 86.5%).
- Claude Opus scores relatively well, but does not match GPT-4o, scoring strongly in DocVQA (89.3%) and AI2D (88.1%).
- Compared to other models, GPT-4o shows superior performance across most evaluation sets.

Language Tokenization Compression Overview:
| Language | Compression Ratio | Example |
|————|——————-|——————————–|
| Gujarati | 4.4x fewer tokens| “હેલો, મારું નામ જીપીટી-4o છે.”|
| Telugu | 3.5x fewer tokens| “నమస్కారము, నా పేరు జీపీటీ-4o.”|
| Tamil | 3.3x fewer tokens| “வணக்கம், என் பெயர் ஜிபிடி-4o.”|
| Marathi | 2.9x fewer tokens| “नमस्कार, माझे नाव जीपीटी-4o आहे.”|
| Hindi | 2.9x fewer tokens| “नमस्ते, मेरा नाम जीपीटी-4o है।”|
| Urdu | 2.5x fewer tokens| “ہیلو، میرا نام جی پی ٹی-4o ہے۔”|
| Arabic | 2.0x fewer tokens| “مرحبًا، اسمي جي بي تي-4o.”|
| Persian | 1.9x fewer tokens| “سلام، اسم من جی پی تی-۴او است.”|
| Russian | 1.7x fewer tokens| “Привет, меня зовут GPT-4o.”|
| Korean | 1.7x fewer tokens| “안녕하세요, 제 이름은 GPT-4o입니다.”|
| Vietnamese | 1.5x fewer tokens| “Xin chào, tên tôi là GPT-4o.”|
| Chinese | 1.4x fewer tokens| “你好,我的名字是GPT-4o。”|
| Japanese | 1.4x fewer tokens| “こんにちわ、私の名前はGPT−4oです。”|
| Turkish | 1.3x fewer tokens| “Merhaba, benim adım GPT-4o.”|
| Italian | 1.2x fewer tokens| “Ciao, mi chiamo GPT-4o.”|
| German | 1.2x fewer tokens| “Hallo, mein Name is GPT-4o.”|
| Spanish | 1.1x fewer tokens| “Hola, me llamo GPT-4o.”|
| Portuguese | 1.1x fewer tokens| “Olá, meu nome é GPT-4o.”|
| French | 1.1x fewer tokens| “Bonjour, je m’appelle GPT-4o.”|
| English | 1.1x fewer tokens| “Hello, my name is GPT-4o.”|
Overview of model safety and limitations:
Safety measures built into the system:
It employs techniques such as filtering training data and refining behavior post-training. Additionally, new safety systems have been devised to monitor voice outputs.
The evaluation process is as follows:
A Preparedness Framework and voluntary commitments have been used to rigorously evaluate GPT-4o. It was assessed for cybersecurity, CBRN (chemical, biological, radiological, and nuclear), persuasion, and model autonomy, with none of these categories exceeding Medium risk. There were both automated and human assessments, as well as safety mitigation prior to and after implementation.
The use of external red teams:
To identify the risks introduced by the newly added modalities, extensive external red teaming was conducted with over 70 experts from social psychology, bias and fairness, and misinformation. As a result of this process, safety interventions were developed to improve it’s overall safety.
The importance of addressing novel risks:
It will initially be released with text and image inputs and outputs in recognition of the novel risks associated with audio modalities. In future releases, technical infrastructure, usability improvements, and safety measures will be implemented for audio outputs, such as preset voices and compliance with safety policies.
The following limitations apply:
Testing and iteration have identified limitations across all modalities of it, and ongoing efforts are underway to address them.
Limitations of the model include:
Soliciting feedback:
We seek input from users to identify tasks where GPT-4 Turbo still outperforms GPT-4o, allowing continuous model improvement.
Overview of model availability:
Over the past two years, we have worked diligently to optimize efficiency across all layers of our system and it marks a significant advancement in our quest to improve deep learning’s practical usability. As a result, we’re thrilled to announce the broader availability of a GPT-4 level model. We’ll be introducing GPT-4o’s capabilities gradually, with extended access for red teaming starting today.
Details of the rollout:
– Capabilities for text and images:
– we’re introducing GPT-4o’s text and image capabilities in ChatGPT. It will be accessible in the free tier and for Plus users, who will enjoy message limits up to 5 times higher. ChatGPT Plus will also launch a new alpha version in the coming weeks that includes its Voice Mode.
Access to APIs:
Developers can now access GPT-4o through the API as a text and vision model. Compared to GPT-4 Turbo, it offers twice the speed, half the price, and five times the rate limits. As soon as possible, we plan to add support for it’s new audio and video capabilities to the API for select partners.











{kind=link}